.png)
Preload e seus perigos
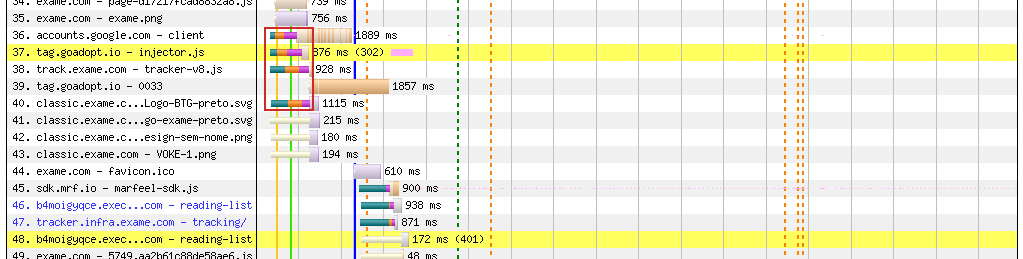
Legenda: Gráfico de cascata de um site usando preload em alguns scripts e um logo. As conexões DNS-TCP-TLS no retângulo vermelho são pré-carregadas, enquanto as conexões embaixo não são pré-carregadas e só são estabelecidas depois que o documento está completo.
Preloading ("pré-carregamento") é, sem dúvidas, uma das técnicas mais comuns de otimização de carregamento de páginas. As métricas de uso do Chrome mostram que, em 2025, quase 50% dos sites usam alguma forma de pré-carregamento, um aumento em relação aos 31% em 2021, quando se tornou padrão. Isso enquadra seu uso como "senso comum," o que é bom, mas também significa que alguns desenvolvedores podem usá-lo sem entender completamente como funciona por trás dos bastidores. Este artigo dará uma breve visão geral do recurso, como utilizá-lo, como ele funciona no navegador e alguns erros comuns.
Com pré-carregamento, o nome entrega o jogo: ele faz o que o nome diz, ele carrega uma coisa antes de outra coisa. Mas se todos os recursos usados numa página precisam ser carregados mais cedo ou mais tarde, e eles são carregados quando seu respectivo elemento HTML é analisado ("parsed"), então como é possível alguns recursos "furarem a fila" e serem pré-carregados? Vamos ver o que a documentação MDN tem a dizer:
O valorpreloaddo atributoreldo elemento<link>permite declarar requisições de busca no<head>do HTML, especificando recursos que sua página precisará em breve e que você deseja começar a carregar logo no início do ciclo de vida da página, antes que o mecanismo principal de renderização do navegador entre em ação. Isso garante que esses recursos estarão disponíveis mais cedo e terão menos chance de bloquear a renderização da página, melhorando o desempenho. Apesar do nome conter o termo load, ele não carrega nem executa o script, só agenda seu download e armazenamento em cache com prioridade mais alta.
(Traduzido; grifo nosso)
Os dois pontos principais aqui são que os recursos pré-carregados são carregados, de alguma forma, antes mesmo da página começar a ser renderizada, e que a etapa que está sendo pulada não é a de análise, mas sim a de download. Isso faz muito sentido, considerando que pré-carregamento é um recurso dos elementos <link>, que são usados para conectar a página a recursos externos.
web.dev nos dá alguns conselhos práticos:
Diretivas depreloaddevem ser limitadas a recursos críticos descobertos tardiamente. Os casos de uso mais comuns são arquivos de fonte, arquivos CSS buscados por meio de declarações@import, ou recursos CSS do tipobackground-image, que são candidatos prováveis a Largest Contentful Paint (LCP). Nesses casos, esses arquivos não seriam descobertos pelo scanner de preload, pois o recurso é referenciado em recursos externos.
(Traduzido)
Parece que realmente queremos pré-carregar recursos de alto impacto: fontes e CSS podem afetar a aparência de toda a página, e o LCP costuma ser o cartão de visitas de um site. Mas o que são “recursos descobertos tardiamente” e “scanner de preload”? Melhor olhar mais de perto como navegadores da internet funcionam.
O que é o scanner de preload?
O processo de transformar marcação, stylesheets, e scripts em uma página web interativa é complicado. O navegador precisa, de alguma forma, traduzir listas de elementos e descrições visuais para um layout com textos e imagens posicionados corretamente, o que significa calcular dimensões, mover elementos, animar, manter referências, e até mesmo executar código. É muita coisa.
Isso começa, é claro, com o próprio HTML sendo analisado. O navegador lentamente constrói o Modelo de Objeto de Documento (DOM) a partir de cada elemento listado, e às vezes essas etapas são demoradas e podem encontrar um recurso que não está na própria página. Ele precisa buscar esses recursos — como alguém seguindo uma receita e percebendo que tem um ingrediente faltando, e que tem que ir ao mercado — e isso atrasa o resto do processo. Felizmente, esse chef já tem alguém para fazer as compras: o scanner de preload. No momento que o HTML chega e começa a ser analisado, o scanner de preload já lê adiante para descobrir o que mais será necessário, como um assistente conferindo quais ingredientes estão faltando e indo buscá-los enquanto o chef está ocupado com outro passo da receita.
Note que o scanner de preload sempre age. Ele não está esperando instruções, e nem falamos sobre elementos <link> com rel="preload" ainda. Isso é porque a diretiva de preload é mais uma dica do que uma instrução. Se o scanner encontrar e carregar algum CSS antes do analisador chegar até ele, ótimo, mas se a stylesheet também depender de imagens externas, mais cedo ou mais tarde chegaremos ao ponto em que o analisador precisa esperar algo chegar para poder continuar seu trabalho. Ao adicionar um <link> de preload para essa imagem no <head> do documento, podemos avisar ao scanner de preload que vamos precisar dela eventualmente, mesmo que não haja menção a ela no HTML.
(Sugerimos o artigo Don't fight the browser preload scanner, em inglês, da web.dev para uma explicação mais detalhada)
Quais são alguns perigos comuns?
Tudo que pode ser feito também pode ser feito errado. Destacamos algumas formas como desenvolvedores podem piorar a performance dos seus sites por mal-uso ou desentendimento do pré-carregamento. Os dois maiores pecados são:
Pré-carregar coisas demais
Esta é quase tautológico. É fácil imaginar como, se tudo for pré-carregado, nada é. A aparência disso na prática é que todos os recursos externos são referenciados e pré-carregados no <head> do documento, como uma enorme lista de compras ocupando o assistente metafórico que poderia estar ajudando o chef a descascar e cortar os ingredientes. Isso vai consumir dados e processamento para carregar agora coisas que poderiam ser tranquilamente carregadas depois (como imagens no final da página), além de atrasar o carregamento dos recursos que são necessários mais cedo. Evite pré-carregar arquivos pesados, como imagens grandes e vídeos, para não atrasar o resto.
Pré-carregar recursos mas não usá-los
Isso pode ser uma surpresa, mas é um erro tão comum que o Chrome e o Firefox tem mensagens de aviso específicas para esses casos. Se alguma vez você inspecionou um site e viu essa mensagem no console, você foi vítima de pré-carregamento espúrio:
The resource <URL> was preloaded using link preload but not used within a few seconds from the window's load event.
Em sua palestra na performance.now() de 2024, Paul Calvano afirma que quase metade dos sites registrados pelo HTTP Archive que pré-carregam dados na verdade não utilizam todos os recursos pré-carregados. Eu teorizo que isso é consequência do problema anterior: um site que possui um carrossel e pré-carrega todas as imagens nunca exibirá todas elas se o usuário não interagir com o carrossel. Se há um ícone no rodapé da página, mas a maioria dos usuários nunca rola até o final, ele nunca será mostrado. Praticamente todos os navegadores usados hoje em dia suportam WOFF2, mas se um desenvolvedor zeloso demais optar por fornecer suas fontes em um segundo formato por precaução, e pré-carregar esse formato alternativo, quase sempre ele acabará sendo um recurso pré-carregado mas não utilizado (e, quando for utilizado, o formato original que será carregado mas não usado).
Conclusão
Seja consciente. O pré-carregamento é um processo automático do navegador que, de vez em quando, vai precisar de uma ajudinha do desenvolvedor. Não existe uma palavra mágica que faça as coisas carregarem mais rápido. Esse assistente de cozinha pode ser muito mais do que apenas um serviçal, mas só se você permitir que ele passe um tempo na cozinha.
Leitura adicional
Algumas recomendações, caso queira aprender mais: